

Learn how Data Lakes Empower Salesforce Data Cloud
Data Lake is Salesforce Data Cloud's Foundation
This article aims to dive deeply into Data Lake and understand how it's powering the Salesforce Data Cloud. Understanding the Data Lake's storage structures, features, use cases and advantages outlined below will make you understand Data Cloud better.
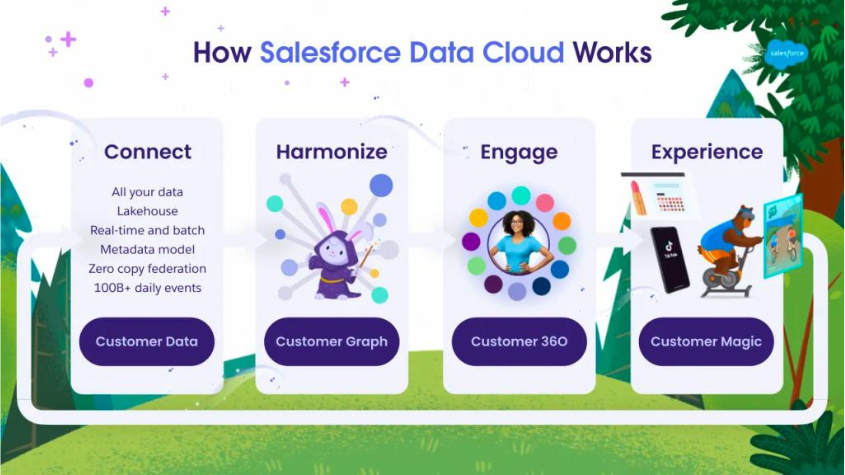
Image Credits - https://trailhead.salesforce.com
What is a Data Lake?
A data lake is a centralised repository designed to store a large amount of raw data in its native format, regardless of the source or structure, unlike a data warehouse, which stores data in a structured format and is optimised for SQL queries.
Data Lake - Supported Data Types
Structured Data: Traditional databases, CSV files, etc.
Semi-Structured Data: JSON, XML files.
Unstructured Data: Text files, social media posts, images, videos.
Data Lake - Use Cases
Here are high-level use cases, followed by industry-specific examples:
Big Data Analytics: Ideal for storing large volumes of data.
Real-Time Analytics: Supports real-time data ingestion and analysis.
Machine Learning: Raw data can be used for training models.
Following Data Lake industry-specific use cases will make it relatable why it's crucial for Salesforce Data Cloud?
Customer 360 Views
Data Sources: CRM systems, social media, transaction databases, customer support logs.
Objective: To create a comprehensive profile of each customer.
Benefits: Improved customer targeting, personalised marketing, and better customer service.
This is also one of the critical highlights of Salesforce Data Cloud and core to Salesforce's offerings lately.

Image Credits - https://www.salesforce.com/ca/products/
Supply Chain Optimisation
Data Sources: Supplier databases, inventory systems, sales records, shipping logs.
Objective: To streamline the supply chain for efficiency and cost-effectiveness.
Benefits: Reduced operational costs, faster delivery times, and better inventory management.
Fraud Detection
Data Sources: Transaction data, user behavior logs, third-party fraud detection feeds.
Objective: To identify and prevent fraudulent activities.
Benefits: Enhanced security, reduced financial losses, and improved customer trust.
Healthcare Analytics
Data Sources: Electronic health records, lab results, wearable device data, insurance claims.
Objective: To improve patient care and optimize healthcare operations.
Benefits: Better diagnosis, personalized treatment plans, and operational efficiencies.
Energy Management
Data Sources: Sensor data from energy grids, weather forecasts, energy consumption data.
Objective: To optimise energy production and distribution.
Benefits: Reduced energy waste, lower costs, and more sustainable energy use.
Financial Market Analysis
Data Sources: Stock market feeds, news articles, social media sentiment, economic indicators.
Objective: To make better investment decisions.
Benefits: Improved portfolio performance, risk mitigation, and market trend identification.
Retail Analytics
Data Sources: Point-of-sale data, online shopping behavior, inventory levels, customer reviews.
Objective: To optimize pricing, inventory, and customer experience.
Benefits: Increased sales, better stock management, and enhanced customer satisfaction.
Smart Cities
Data Sources: Traffic cameras, weather stations, public transportation systems, utility grids.
Objective: To improve public services and quality of life.
Benefits: Reduced traffic congestion, better public safety, and more efficient public services.
Advantages of Data lake
The following advantages are mostly related to Data lakes, but it's easy to correlate and make sense of the value they bring to the Salesforce Data Cloud.
Highly Scalable: Can easily accommodate growing volumes of data.
Elasticity: Scale up or down based on demand, especially in cloud-based solutions.
Diverse Data Types: Supports structured, semi-structured, and unstructured data.
Schema-on-Read: Allows you to define the schema at the time of reading, offering more flexibility in data storage.
Lower Storage Costs: Generally cheaper per unit of storage compared to traditional databases.
Pay-as-You-Go: Cloud-based solutions often offer pay-as-you-go pricing models.
Single Repository: Centralizes data from multiple sources, making it easier to manage and analyze.
Batch and Stream Ingestion: Supports both batch and real-time data ingestion.
Machine Learning: Raw data can be used directly for machine learning models.
Real-Time Analytics: Capable of handling real-time data for instant insights.
Metadata Management: Enhanced metadata features via tags for better data governance.
Data Lineage: Ability to track the source and transformations of data.
Quick Setup: Faster to set up compared to traditional data warehouses.
Rapid Prototyping: Easier to experiment with new data models and analytics.
Encryption: Strong encryption options for data at rest and in transit.
Access Control: Role-based access controls for better data security.
API Support: Easy integration with various analytics and data processing tools.
Open Formats: Supports open data formats like JSON, Parquet, and Avro.
Data Lake Architecture
Storage Layer: The foundational layer where raw data is stored. It could be on-premises or cloud-based.
Data Processing Layer: Where data is transformed, cleaned, and enriched.
Data Access Layer: Provides interfaces for data retrieval and analytics.
Data Ingestion
Batch Ingestion: Data is ingested in large batches, typically at scheduled intervals.
Stream Ingestion: Real-time ingestion of data as it is generated.
These both forms of ingestions are well suited for Salesforce Data Cloud customers.
Data Catalog and Metadata
Catalog: An organized inventory of data that helps users find the data they need.
Metadata: Information about the data, like source, structure, and access permissions, helps in data discovery and governance.
Tags in Data Lake
Labeling: Help identify data assets.
User-Defined: Customizable, e.g., "financial data" or "Q4 reports."
Searchability: Enhance data discovery.
Lineage: Track data source and changes.
Access: Control user permissions.
Metadata Tags
System-Generated: Auto-created by the system.
Description: Detail data type, size, etc.
Relationships: Show how data is linked.
Query: Optimize search queries.
Compliance: Store regulatory info like retention policies.
Security and Compliance
Encryption: Data is encrypted both in transit and at rest.
Access Control: Role-based access control to ensure only authorized users can access data.
Audit Trails: Logs to track who accessed what data and when, for compliance purposes.
Salesforce does need all of this security and compliance to make sure Salesforce Data Cloud can be used for the largest enterprises.
Querying and Analysis
SQL Interfaces: Many data lakes offer SQL-based querying for structured data.
NoSQL Interfaces: NoSQL queries may be used for semi-structured and unstructured data.
Data Lake Engines: Specialized engines like Dremio or Presto can be used for faster querying.
Popular Data Lake Solutions
Cloud-Based Solutions
Amazon S3: Highly scalable and secure, integrates well with other AWS services like Athena for querying.
Azure Data Lake Storage: Offers tight integration with Azure services and supports both structured and unstructured data.
Google Cloud Storage: Known for high-speed data access and seamless integration with Google's analytics and machine learning tools.
On-Premises Solutions
Hadoop Distributed File System (HDFS): Open-source and highly scalable, often used as the storage layer in big data projects.
Dell EMC Isilon: Offers high performance and scalability, suitable for enterprises with complex storage needs.
Hybrid Solutions
IBM Cloud Object Storage: Can be deployed on-premises, in the cloud, or as a hybrid solution, offering flexibility.
NetApp StorageGRID: Supports a mix of cloud and on-premises storage, focusing on data compliance and security.
Specialised Data Lake Engines
Dremio: A data lake engine that accelerates query performance and simplifies data access.
Presto: An open-source distributed SQL query engine designed for running interactive analytic queries against data lakes.
Data Lake Platforms
Cloudera Data Platform: An enterprise-grade solution that combines data lakes, data warehouses, and machine learning.
Snowflake: Though primarily a data warehouse, it offers data lake features and can query semi-structured data.
Open-Source Solutions
MinIO: An open-source object storage server compatible with Amazon S3, often used for building private clouds.
Ceph: An open-source storage platform that provides object, block, and file storage in a single unified system.
Thanks
I hope you enjoyed this post, my goal here was to understand more about Salesforce Data Cloud internals, and it was a delight when I was exploring and digging more into Data Lakes, and the value they are bringing to the table.
Look at the following video to see how the above Data Lake concepts play a role in the Salesforce Data cloud:
Learn more about Data Cloud
Official Salesforce Data Cloud Landing Page - https://www.salesforce.com/products/data/
Salesforce Data Cloud | Partner Pocket Guide : https://quip.com/wCQnAww3wBr0
Data Cloud Feature Release Hub for Partners - https://quip.com/VvkmAimW4o4P
For Salesforce Partners, check the offering in learning Camp - https://partnerlearningcamp.salesforce.com/s/learner-dashboard?recordId=a5p3m000000Ho5bAAC&itemType=Journey